Data Lifecycle
Data Lifecycle manages the retention of events, service groups, Chef Infra Client runs, compliance reports and scans in Chef Automate. Chef Automate stores data from the ingest-service,event-feed-service, compliance-service and applications-service in Elasticsearch or PostgreSQL. Over time, you may wish to remove that data from Chef Automate by using the data lifecycle settings.
Warning
Data Lifecycle UI
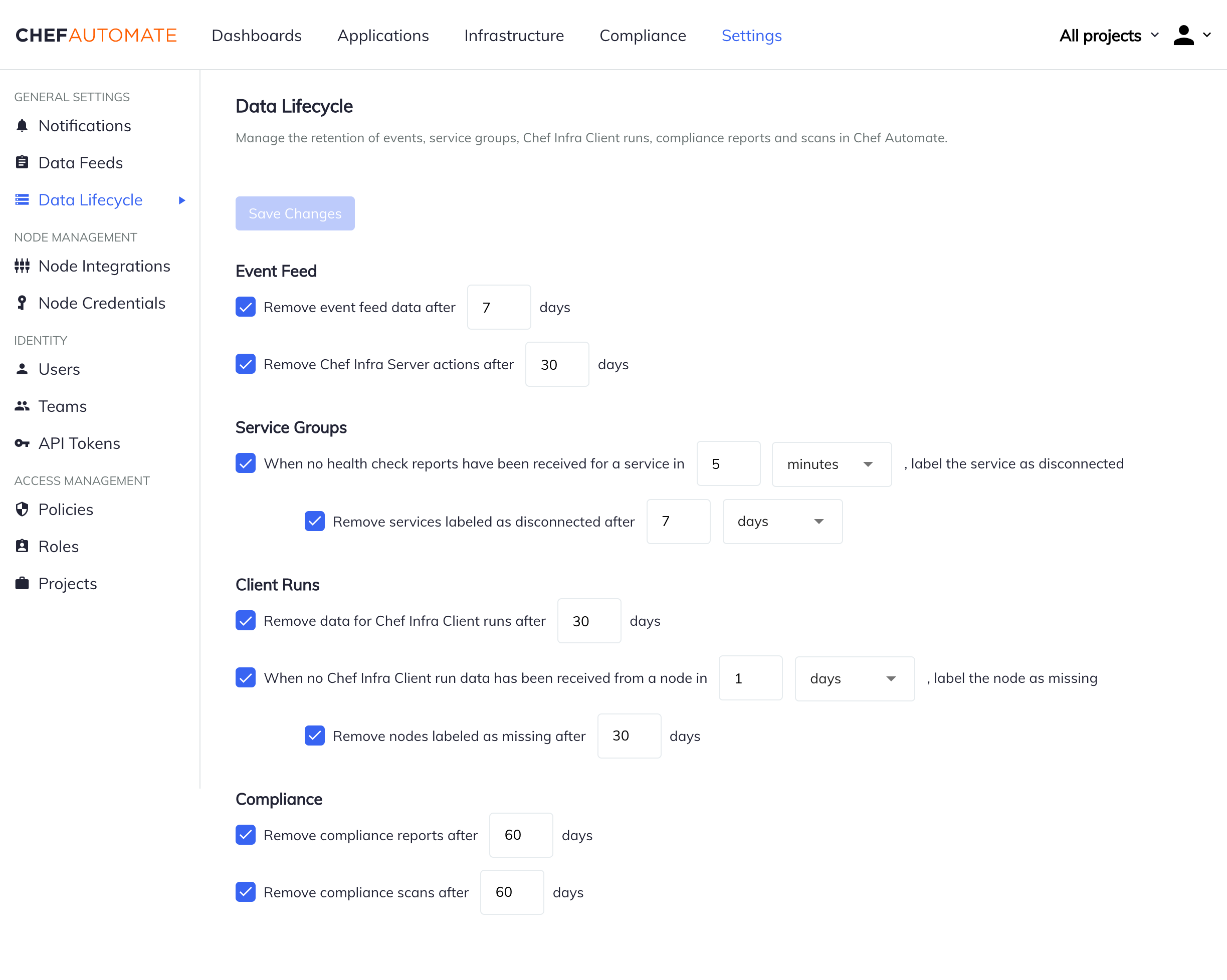
Navigate to Settings > Data Lifecycle and adjust any settings you would like to change. After making changes, use the Save Changes button to apply your changes.
Users with dataLifecycle:* IAM access are able to see the data lifecycle job statuses, configure jobs, or run jobs.
Event Feed
The Event Feed Data Lifecycle settings allow you to remove all event feed data and Chef Infra Server actions after a set amount of days. The default is to remove event feed data after 7 days, and Chef Infra Server actions after 30 days.
Service Groups
The Service Group Data Lifecycle settings allow you to label health check reports as disconnected and automatically remove them after a set amount of time. The default is to label health check reports as disconnected after 5 minutes, and remove disconnected services after 7 days.
Client Runs
The Client Runs data lifecycle settings allow you to remove data after a set amount of days. They also allow you to label nodes as missing and automatically remove them after a set amount of days. The default is to remove Chef Infra Client run data after 30 days, to label nodes as missing after 1 day, and to remove nodes labeled as missing after 30 days.
Compliance
The Compliance data lifecycle settings allow you to remove compliance reports and compliance scans after a set amount of days. The default is to remove compliance reports after 60 days, and to remove compliance scans after 60 days.
Data Lifecycle API
Chef Automate stores data from the ingest-service, event-feed-service, compliance-service and applications-service in Elasticsearch or PostgreSQL.
The data-lifecycle API allows configuring and running lifecycle jobs by data type:
infra- Chef Infra Server actions and Chef Infra Client converge datacompliance- Chef InSpec reports and Chef Compliance scansevent-feed- Event metadata that powers the operational visibility and query languageservices- Chef Habitat Services data
To see the data lifecycle job statuses, configure jobs, or run jobs requires an api token with dataLifecycle:* IAM access.
Status
To see the combined status and configuration for all data lifecycle jobs, you can use the global status endpoint:
curl -s -H "api-token: $TOKEN" https://automate.example.com/api/v0/data-lifecycle/status
To see individual statuses by data type, you can access the data type sub-status endpoints:
curl -s -H "api-token: $TOKEN" https://automate.example.com/api/v0/data-lifecycle/event-feed/status
Swap event-feed for infra or compliance or services to see their corresponding jobs.
The status is the total of the job configuration, details about its next scheduled run, and details about any previous runs.
Configuration
Configure the data lifecycle job settings by creating a JSON file with the desired configuration.
{ "infra": {
"job_settings": [
{ "name":"delete_nodes",
"disabled": true,
"recurrence": "FREQ=MINUTELY;DTSTART=20191106T180240Z;INTERVAL=15",
"threshold": "365d"
},
{ "name":"missing_nodes",
"disabled": false,
"recurrence": "FREQ=MINUTELY;DTSTART=20191106T180240Z;INTERVAL=15",
"threshold": "1d"
},
{ "name":"missing_nodes_for_deletion",
"disabled": false,
"recurrence": "FREQ=MINUTELY;DTSTART=20191106T180240Z;INTERVAL=15",
"threshold": "30d"
},
{ "name":"periodic_purge_timeseries",
"disabled": false,
"recurrence": "FREQ=DAILY;DTSTART=20191106T180240Z;INTERVAL=1",
"purge_policies": {
"elasticsearch": [
{
"policy_name": "actions",
"older_than_days": 30,
"disabled": false
},
{
"policy_name": "converge-history",
"older_than_days": 30,
"disabled": false
}
]
}
}
]
},
"compliance": {
"job_settings": [
{
"name": "periodic_purge",
"disabled": false,
"recurrence": "FREQ=DAILY;DTSTART=20191106T180323Z;INTERVAL=1",
"purge_policies": {
"elasticsearch": [
{
"policy_name": "compliance-reports",
"older_than_days": 100,
"disabled": false
},
{
"policy_name": "compliance-scans",
"older_than_days": 100,
"disabled": false
}
]
}
}
]
},
"event_feed": {
"job_settings": [
{
"name": "periodic_purge",
"disabled": false,
"recurrence": "FREQ=DAILY;DTSTART=20191106T180243Z;INTERVAL=2",
"purge_policies": {
"elasticsearch": [
{
"policy_name": "feed",
"older_than_days": 90,
"disabled": false
}
]
}
}
]
},
"services": {
"job_settings": [
{
"name": "disconnected_services",
"disabled": false,
"recurrence": "FREQ=SECONDLY;DTSTART=20200612T182105Z;INTERVAL=60",
"threshold": "5m"
},
{
"name": "delete_disconnected_services",
"disabled": false,
"recurrence": "FREQ=SECONDLY;DTSTART=20200612T182105Z;INTERVAL=60",
"threshold": "7d"
}
]
}
}
Configure the jobs by sending the JSON payload to the config endpoint.
Note
config endpoint intentionally follows a different format than the data returned from the status endpoint.
You cannot read the data on the status endpoint, change some values, and feed the modified data back on the config endpoint.Save the JSON file as config.json in the current working directory:
curl -s -H "api-token: $TOKEN" -X PUT --data "@config.json" https://automate.example.com/api/v0/data-lifecycle/config
If you wish to configure a specific endpoint, you can specify the job_settings for that data type and configure it using data types sub-resource.
For example, if you want to configure compliance settings, create a smaller JSON payload:
{ "job_settings": [
{
"name": "periodic_purge",
"disabled": false,
"recurrence": "FREQ=DAILY;DTSTART=20191106T180323Z;INTERVAL=1",
"purge_policies": {
"elasticsearch": [
{
"policy_name": "compliance-reports",
"older_than_days": 100,
"disabled": false
},
{
"policy_name": "compliance-scans",
"older_than_days": 100,
"disabled": false
}
]
}
}
]
}
And update the specific endpoint using the compliance sub-resource:
curl -s -H "api-token: $TOKEN" -X PUT --data "@config.json" https://automate.example.com/api/v0/data-lifecycle/compliance/config
Job Settings
All jobs have the following options:
recurrence(string) - A recurrence rule that determines how often, at what interval, and when to initially start a scheduled job. Any valid recurrence rule as defined in section 4.3.10 of RFC 2445 is valid in this field.disabled(bool) - True or false if this job is enabled.
Infra node lifecycle jobs have the following options:
threshold(string) - Setting that allows the user to use1wstyle notation to denote how long before the Infra job triggers.
Purge jobs have the following options:
purge_polices(map) - Configures how old the corresponding data must be in the configured storage backend before purging occurs.elasticsearch(array) - An array of Elasticsearch purge policiesdisabled(bool) - True or false if this job is enabled.policy_name(string) - The name of the purge policy you wish to update.older_than_days(int) - The threshold for what qualifies for deletion.
Services jobs have the following options:
threshold(string) - Setting that allows the user to use1mstyle notation to select the services the task operates on.
Infra Job Settings
The infra data type has four data lifecycle jobs: three are for node lifecycle and one is for purge job with two Elasticsearch purge policies.
{ "job_settings": [
{ "name":"delete_nodes",
"disabled": true,
"recurrence": "FREQ=MINUTELY;DTSTART=20191106T180240Z;INTERVAL=15",
"threshold": "365d"
},
{ "name":"missing_nodes",
"disabled": false,
"recurrence": "FREQ=MINUTELY;DTSTART=20191106T180240Z;INTERVAL=15",
"threshold": "1d"
},
{ "name":"missing_nodes_for_deletion",
"disabled": false,
"recurrence": "FREQ=MINUTELY;DTSTART=20191106T180240Z;INTERVAL=15",
"threshold": "30d"
},
{ "name":"periodic_purge_timeseries",
"disabled": false,
"recurrence": "FREQ=DAILY;DTSTART=20191106T180240Z;INTERVAL=1",
"purge_policies": {
"elasticsearch": [
{
"policy_name": "actions",
"older_than_days": 30,
"disabled": false
},
{
"policy_name": "converge-history",
"older_than_days": 30,
"disabled": false
}
]
}
}
]
}
delete_nodes- How long a node can exist before deletion.missing_nodes- How long between a node’s last check-in before marked as missing.missing_nodes_for_deletion- How long a node can be missing before deletionperiodic_purge_timeseries- How often to run the purge jobactions- Chef Infra Server actionsconverge-history- Chef Infra Client converge data
Compliance Job Settings
The compliance data type has one compliance purge job with two Elasticsearch purge policies.
{ "job_settings": [
{
"name": "periodic_purge",
"disabled": false,
"recurrence": "FREQ=DAILY;DTSTART=20191106T180323Z;INTERVAL=1",
"purge_policies": {
"elasticsearch": [
{
"policy_name": "compliance-reports",
"older_than_days": 100,
"disabled": false
},
{
"policy_name": "compliance-scans",
"older_than_days": 100,
"disabled": false
}
]
}
}
]
}
periodic_purge- How often to run the purge jobcompliance-reports- Chef InSpec reportscompliance-scans- Chef Compliance scans
Event Feed Job Settings
The event_feed data type has one event feed purge job with one Elasticsearch purge policy.
{ "job_settings": [
{ "name": "periodic_purge",
"disabled": false,
"recurrence": "FREQ=DAILY;DTSTART=20191106T180243Z;INTERVAL=2",
"purge_policies": {
"elasticsearch": [
{
"policy_name": "feed",
"older_than_days": 90,
"disabled": false
}
]
}
}
]
}
periodic_purge- How often to run the purge jobfeed- Queryable event feed
Services Job Settings
The services data type has two jobs, one to mark services as disconnected
when the elapsed time since Chef Automate last received a health check message
exceeds the threshold, and one to delete services when the time since the last
health check exceeds the threshold.
{ "job_settings": [
{
"name": "disconnected_services",
"disabled": false,
"recurrence": "FREQ=SECONDLY;DTSTART=20200612T182105Z;INTERVAL=61",
"threshold": "5m"
},
{
"name": "delete_disconnected_services",
"disabled": false,
"recurrence": "FREQ=SECONDLY;DTSTART=20200612T182105Z;INTERVAL=61",
"threshold": "7d"
}
]
}
Run
As with status and configure, you can run data lifecycle jobs globally across all data or by using the data type sub-resource.
To run all data lifecycle jobs, run the following command:
curl -s -H "api-token: $TOKEN" -X POST https://automate.example.com/api/v0/data-lifecycle/run
To run jobs for a specific data type, you can make the request to the sub-resource:
curl -s -H "api-token: $TOKEN" -X POST https://automate.example.com/api/v0/data-lifecycle/infra/run
Swap infra for event-feed or compliance to run their corresponding jobs.
Was this page helpful?